
*경진대회 및 데이터 분석의 과정
[문제 파악] - [데이터 탐색] - [데이터 전처리] - [모델 학습] - [예측]
위의 과정에 따른 간단한 머신러닝 프로젝트를 만들어보겠습니다.
[문제 파악]
x = [-3, 31, -11, 4, 0, 22, -2, -5, -25, -14]
y = [ -2, 32, -10, 5, 1, 23, -1, -4, -24, -13]
print(x)
print(y)각 10개의 숫자를 원소로 갖는 리스트 x와 y가 있습니다.

둘은 y= x + 1 관계에 있습니다.
[데이터 탐색]
import matplotlib.pyplot as plt
plt.plot(x, y)
plt.show()맷플록립(matplolib) 패키지를 활용해 x, y 변수 사이의 관계식을 그래프로 그려봅니다.
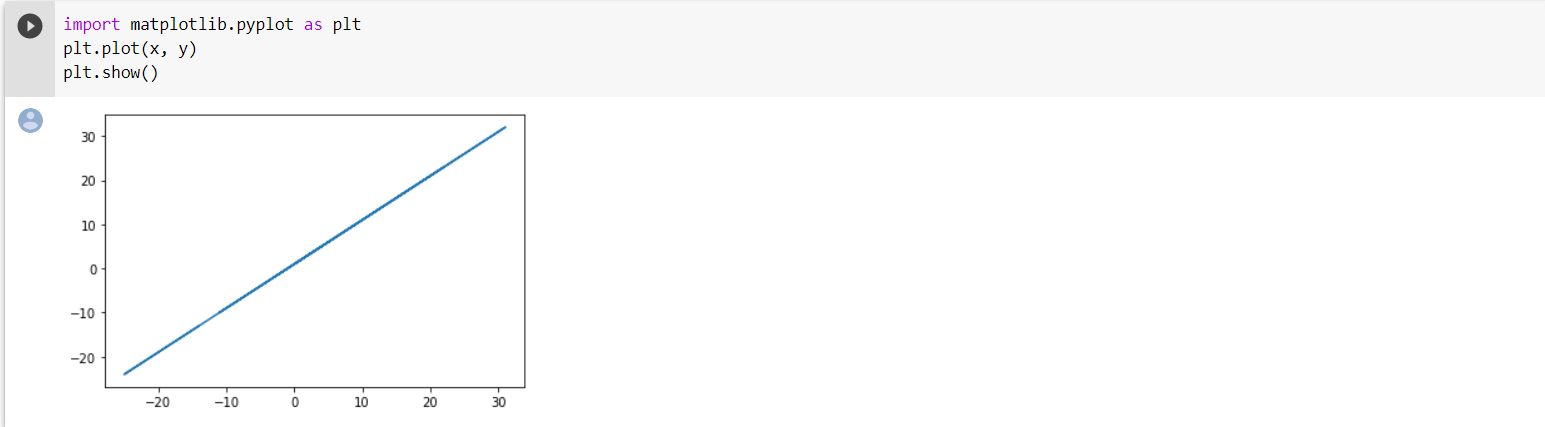
가로축은 x, 세로축은 y입니다.
[데이터 전처리]
import pandas as pd
df = pd.DataFrame({'X':x, 'Y':y})
df.shape판다스를 통해 데이터프레임을 만듭니다.
이때 x 리스트는 'X' 열의 데이터, y 리스트는 'Y' 열의 데이터로 변환됩니다.

shape 속성을 통해 (10행, 2열) 구조임을 확인할 수 있습니다.
df.head()head 메소드는 첫 5개의 행 (인덱스 0~4)을 추출해서 보여줍니다.

첫 5행의 출력을 확인할 수 있습니다.
df.tail()반대로 tail 메소드는 마지막 행을 보여줍니다.

마지막 5행의 출력을 확인할 수 있습니다.
train_features = ['X']
target_cols = ['Y']
X_train = df.loc[:, train_features]
y_train = df.loc[:, target_cols]
print(X_train.shape, y_train.shape)설명 변수(X)를 만듭니다.
'X'열의 데이터를 선택해서 X_train에 저장합니다.
목표 변수(Y)를 만듭니다.
'Y'열의 데이터를 선택해서 y_train에 저장합니다.

[모델 학습]
머신러닝 알고리즘을 적용하여 선형 회귀 관계식을 찾아봅니다.
from sklearn.linear_model import LinearRegression
lr = LinearRegression()
lr.fit(X_train, y_train)LinearRegression클래스 함수는 선형회귀 모델을 구현해 놓은 코드라 보면 됩니다.
모델 인스턴스 객체를 생성하고 lr변수에 저장합니다.
fit 메소드는 입력 데이터를 모델에 전달하여 학습시키는 함수 명령입니다.

입력 데이터(X_train)와 목표 레이블(y_train)을 전달하면 선형 관계식을 찾습니다.
lr.coef_, lr.intercept_학습을 끝낸 lr 모델 인스턴스 객체의 coef_ 속성으로부터 X변수의 회귀계수(기울기)를 얻을 수 있습니다.

intercept_ 속성은 상수항(y 절편)을 나타냅니다.
print ("기울기: ", lr.coef_[0][0])
print ("y절편: ", lr.intercept_[0])기울기와 y절편을 출력합니다.

기울기가 1이고, 상수항이 1이므로, lr 모델은 Y = X + 1의 관계식을 갖습니다.
[예측]
import numpy as np
X_new = np.array(11).reshape(1, 1)
lr.predict(X_new)학습을 마친 모델에 predit 메소드를 적용하면 새로운 입력 데이터에 대한 레이블을 예측할 수 있습니다.
X_train이 2차원 구조이므로 predit의 메소드 입력값 또한 2차원 구조로 동일해야 합니다.

넘파이(numpy) 라이브러리의 array 함수로 숫자 11을 배열로 변환하고, reshape 메소드를 적용하여 (1행, 1열) 형태의 2차원 구조로 변형합니다.
X_test = np.arange(11, 16, 1).reshape(-1, 1)
X_testpredit 메소드의 입력 데이터로 여러 개의 숫자를 사용합니다.
넘파이 모듈의 arrange 함수를 사용합니다. np.arrange(11, 16, 1)은 11부터 15까지(16 제외) 정수를 1의 간격을 두고 1차원 배열을 만듭니다.
여기에 reshape(-1, 1) 메소드를 적용하면 (n행, 1열) 형태의 2차원 구조로 변환됩니다.

-1은 크기가 정해지지 않았다는 의미입니다.
y_pred = lr.predict(X_test)
y_predpredit 메소드 함수에 X_test 배열을 입력해서 y_pred 값을 예측합니다.

Y = X + 1의 관계식을 갖는 모델이므로 12부터 16의 숫자 배열이 반환됩니다.
본 내용은 '파이썬 딥러닝 머신러닝 입문'을 기반으로 공부한 내용을 정리한 글입니다.
'머신러닝' 카테고리의 다른 글
| [머신러닝] 분류 - 붓꽃의 품종 판별 -1 (0) | 2022.04.28 |
|---|---|
| [머신러닝] 머신러닝 (0) | 2022.04.28 |
| [머신러닝] 판다스 자료구조 (0) | 2022.04.28 |